


As everyone knows the Cluster index will be stored as a B-Tree structure in an organized mannered data, the Cluster index will be Sorted and stored physically in the same table from the Heap Table and it will not create any separate space.
Why do we need to use the Cluster Store Index?
- To reduce the Storage cost
- We can reduce the amount of I/O while searching the data.
- Fast retrieval of data
Structure of Cluster Index
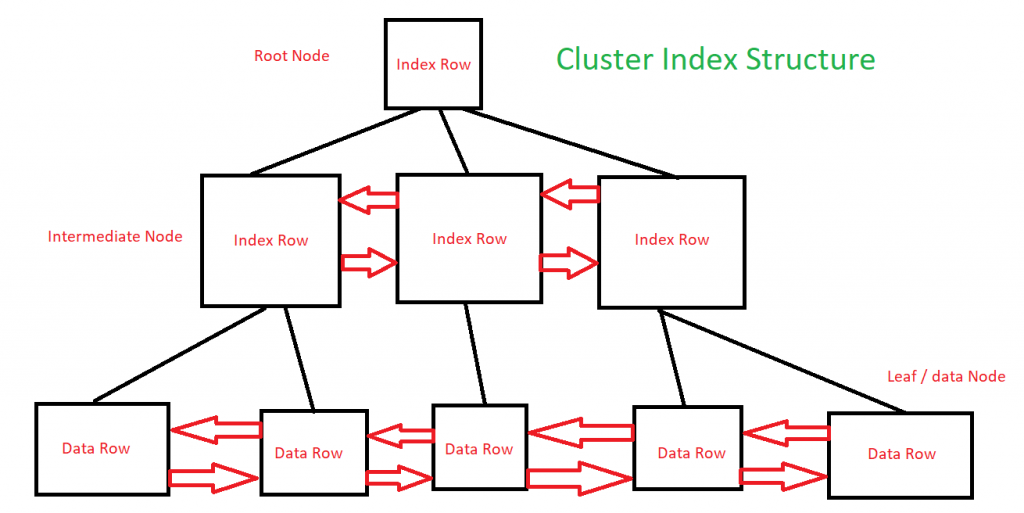
SQL Server engine creates the unique key automatedly for reach row even if the table does not have any unique record.
NOTE: When we will create a primary key, the Cluster Index will be created automatedly
SYNTAX
CREATE CLUSTERED INDEX <Index_Name> ON <Table Name> (Column Name);
How does Cluster Index work?
Let go with some examples of how Cluster Index works. Here I am taking one student details with columns of Std_id and Std_Name
- Here Std_id records are not interest as sequency like 1001,1002,1003,1004,1005…
- We don’t have a primary column in this table ( No Cluster index )
CREATE TABLE [dbo].[studentDetails]( [Std_id] [int] NOT NULL, [Std_Name] [varchar](50) NULL ) ON [PRIMARY] GO INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1005, N'Prabhakaran') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1006, N'Ram') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1003, N'Prabhakaran') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1004, N'Radha') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1001, N'Ram') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1011, N'Prabhakaran') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1007, N'Lakshana') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1008, N'Radha') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1009, N'Ram') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1015, N'Prabhakaran') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1014, N'Lakshana') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1013, N'Radha') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1002, N'Ram') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1012, N'Prabhakaran') INSERT [dbo].[studentDetails] ([Std_id], [Std_Name]) VALUES (1010, N'Lakshana')
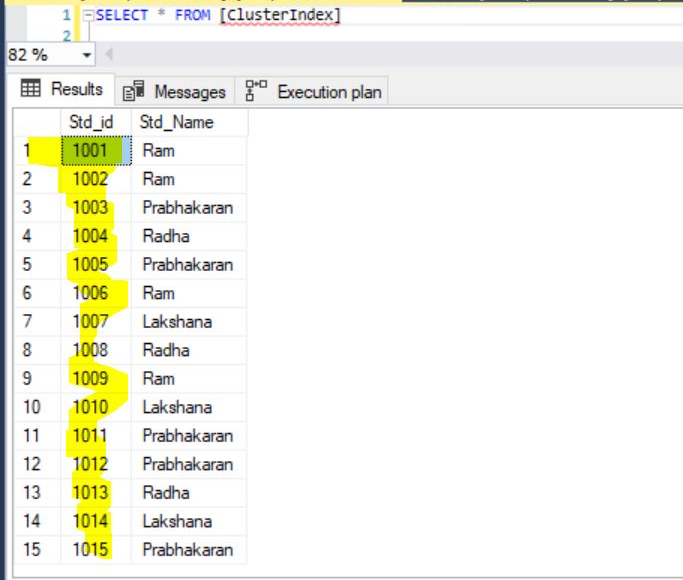
After Insert the record and you can see the result like below when you are select all records from the table.
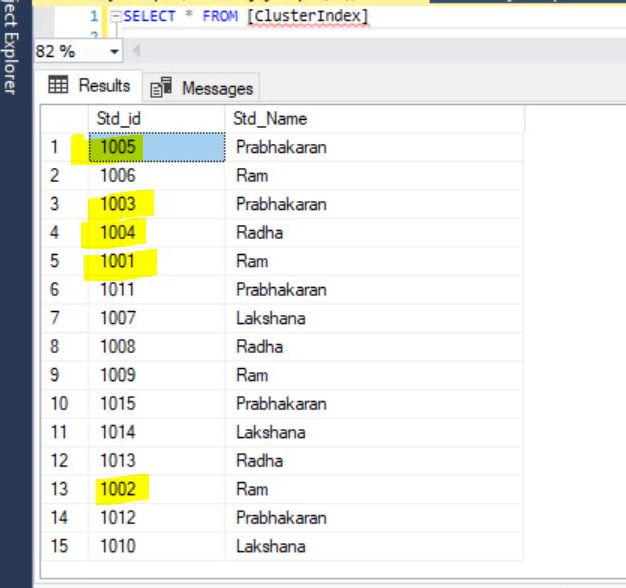
And also, you can see here Table Scan will happen while selecting all records from the Clusterindex table. Because we don’t have a Cluster index in this table. SQL Server Optimizer will do Table Scan in execution.
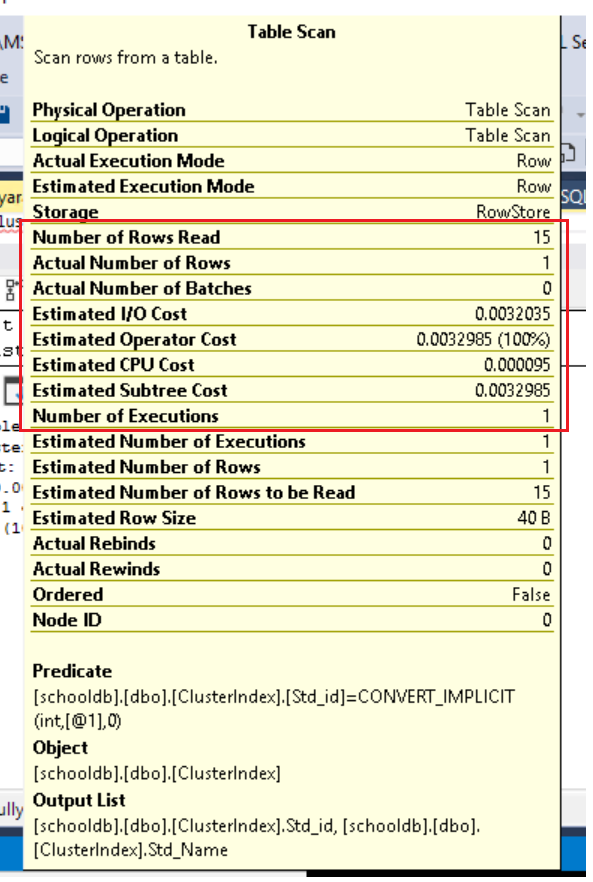
What is Table Scan:? When the SQL Server Optimizer does a complete scan row by row searching to collect the data that is called “Table Scan”. We can see the in-Execution plan, in this execution, SQL server Optimizer does Table Scan operation.
Let take an example we are selecting one record from the table and SQL Server Optimizer will do select the one record from the table when we don’t have an index in the table.
Here we are selecting std_id which have 1011 and the data selected from the table., now if you see the execution plan

If you see here, Total Number of Rows Reads 15 and actual Number of Rows 1, the Estimated Subtree cost also 0.0032985. The Problem here SQL server optimizer will read the completed table to pull the one record. So the Subtree, I/O, and CPU Costs are more expensive for selecting one record.
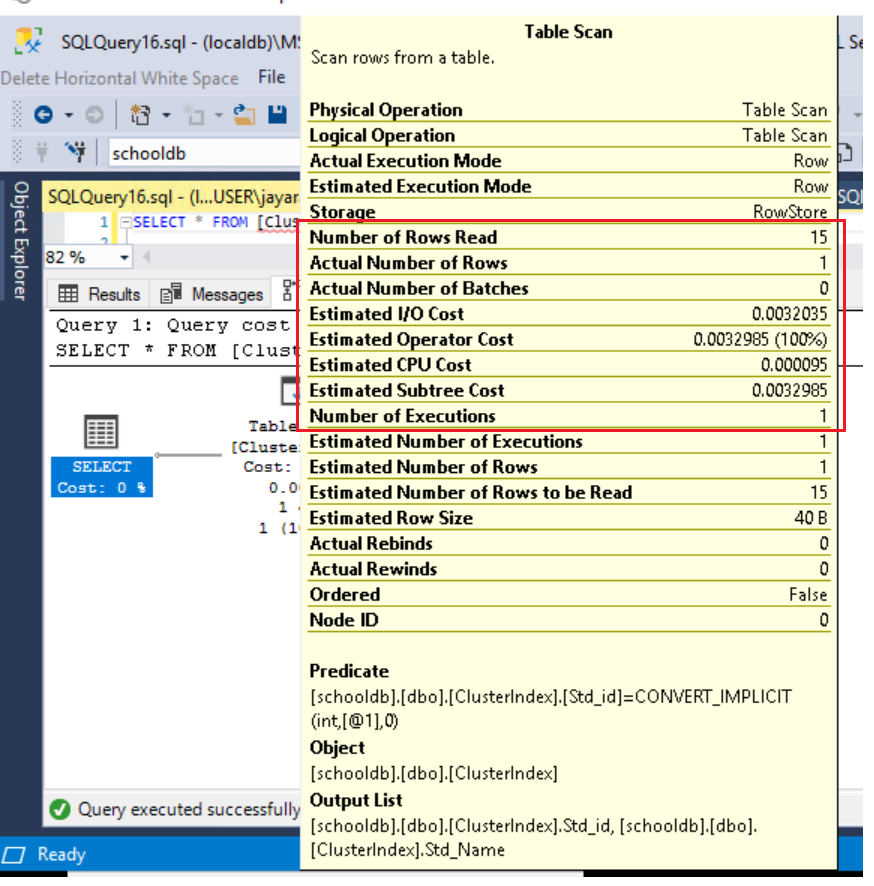
How we can reduce this cost.? Yes, Here we can create the Cluster index to sort the data and pull the required output to reduce search cost.
Let’s create the Cluster index on the Std_id. As I have told above by creating the Primary key, we can create a Cluster index, or you can directly from the T-SQL by using Cluster index syntax.
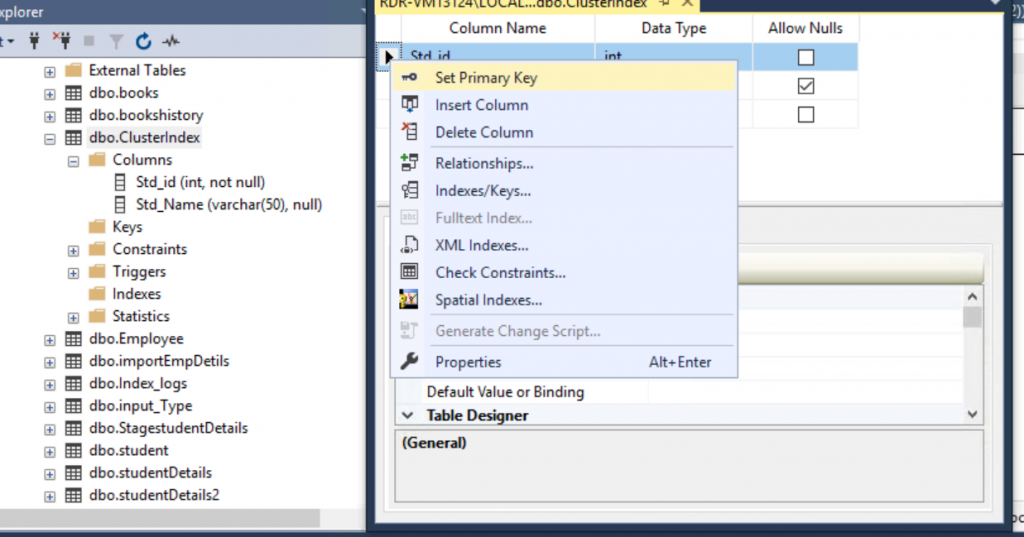
After created the Primary key against Std_Id, now you can see the Cluster index created automatedly.
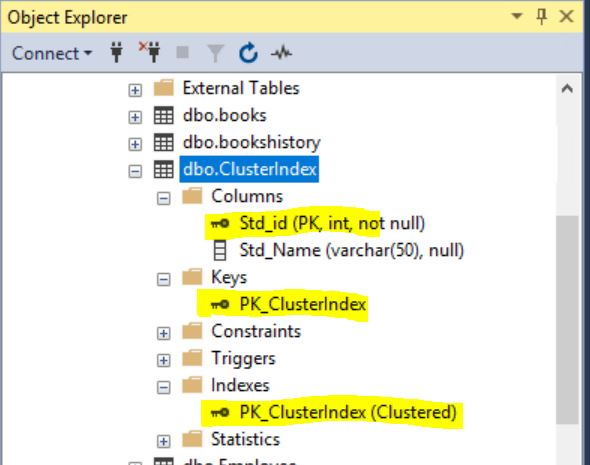
Now you select all records from the table, you can the data will be sorted automatedly and stored in the Physical table itself, this is called Cluster Index. Have look at the below snapshot.
And you see the difference in the Execution plan. Now SQL Optimizer will do Cluster Index Seek., it’s mean that SQL Optimizer searches the record based on B-Tree Search instead of going one by one.
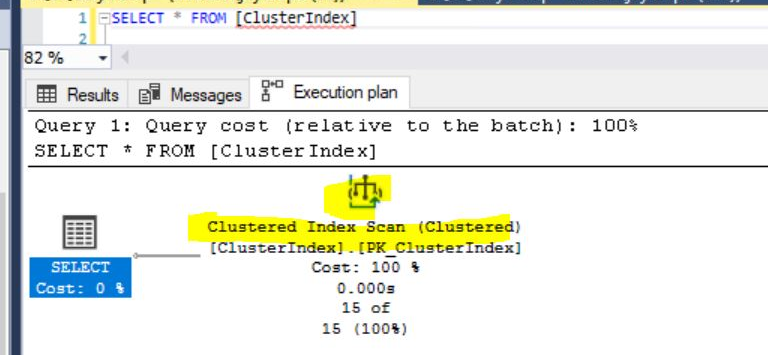
Now we can select one record from the table and see the Cluster Index Seek Properties, The Actual number of Rows Read will be 1, and the Actual Number of Rows 1 and No Batches here.
The Estimated Subtree Cost is 0.0032832, before you see the cost is 0.0032985. We gained better performance after created the Cluster Index. Maybe here we can see some small difference in the tree cost. But just imagine we are a select record from the table that have million + records.
Thank You.



Leave a Reply